
I’ve had some problems with marvel.com and a swedish movie site named MovieZine(.se). None of them offers RSS feeds, but that doesn’t change that I’m highly interested in their content.
Ever since the first data collector project died, I’ve been planning to recreate it since it not only offers the ability to follow sites without RSS with RSS. The first project also was keeping track on changes in articles so you could easily see what was changed from each edit the sites made. However, the rebirth of the “RSSWatch” project is not intended to track changes even if the Tools API actually have this opportunity.
So, how do I follow sites without RSS and what is the purpose?
The purpose of this project is to attract visitors to the sites that we actually monitor. By giving more instant information from respective site where visitors can quickly jump into, without being forced to monitor a mail-feed or enter a website each day, the intentions with this project is to actually auto update users that is interested in the content.
With automation we can also start offer “featured content” with a single page where content are collected with RSS data, so it can be quickly shared over for example Facebook or your own customized website.
The Progress this far
This weekend, I finalized a first draft that turned out to work really well. It not only fetches REST-collected data, it can also fetch data instantly from “pre formatted” websites. By means, if a website has an automatically generated layout (umm, not with ReactJS, yet, though), data can in a very simple way get collected in a format that fits RSS.
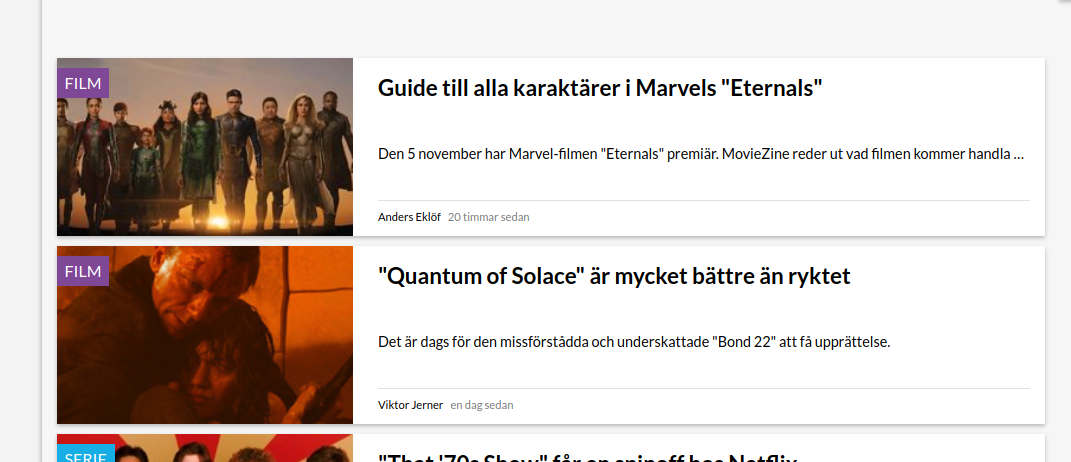
Our first really heavy example is MovieZine as mentioned above. They do have articles, but they are not propagated with a RSS feed. Instead they offer email subscriptions and other account based features. For me, I’m mostly interested in the Marvel content, but I don’t always have time to go look for new content on all websites I monitor. This is where the RSS project kicks in. As you can see in this example, we are now able to collect the main content of each article (and the intentions is to not read the entire articles either, scraping off data from the sites entirely). Instead, we want to make it possible to keep up on sites that do not offer this feature, so that it will be easier to quickly enter articles that we are explicitly interested in.
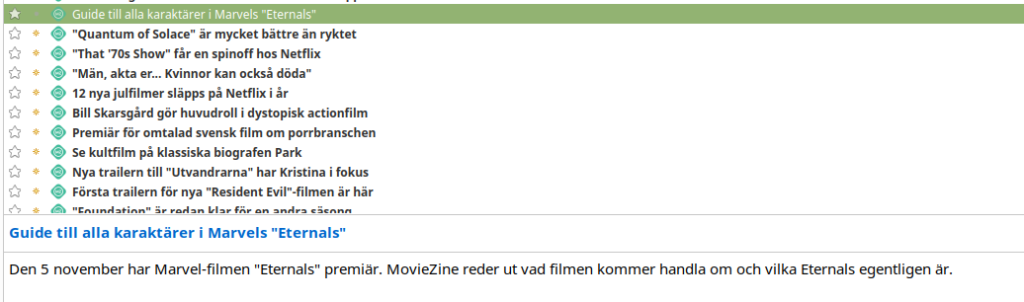
For now, we have just a few RSS feeds up, and they can be found at the ToolsAPI. Just make sure you have json-parser, when you check this out. Initially, by just entering https://tools.tornevall.net/api/rss/feed/, will give you very much the urls available for feedreading. When you have the proper id or title (as the feed is very much searchable on sites) you can start fetching the feeds.
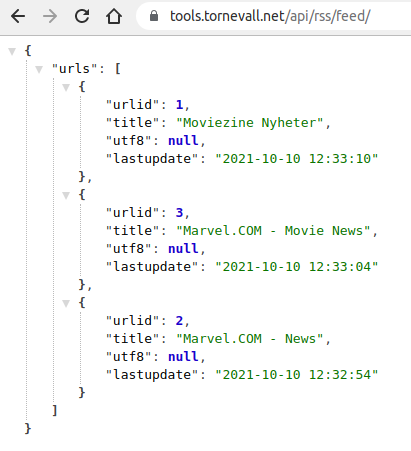
For example, to get the feed for urlid 3, you go to https://tools.tornevall.net/api/rss/feed/3. For a merged version, where you merge urlid 2 and 3, you instead enter the parts of the title like this: https://tools.tornevall.net/api/rss/feed/marvel.com.
By adding ?as=json to the feed-urls, the content will stop publish itself as XML/RSS and instead as json. You can try it out here!
Are we missing Marvel-related sites you want to keep your eyes on? You can contact us via “About earth616.org“.
One Comment on “My favourite site does not have RSS but I’d like to follow them”